Managing a Studbook
My aim in this gist is to show how a graph database is an environment where to manage genealogies in a very natural way.
I will deal with genealogies of horses, which are generally managed in a Studbook by an institution that must ensure the correctness of the information and the compliance of the data with specific conditions.
The gist will show:
-
how to register horses in the Studbook,
-
how to check some consistency conditions,
-
how to manage the relationships of the horses with owners, breeders and tenants,
-
how to manage a purchase of a horse and
-
how to query information from the Studbook, like horse’s pedigree, ancestors or descendants.
We suppose here that the horses are registered in the Studbook only with some basic data: name, year of birth, gender, mantle. We also suppose that the horses are all thouroughbreds, so that we can not worry about breed compatibility. Many other data could be registered, such as race and percentage of Arabian blood (when the Studbook is for crossbreds, like Anglo-Arabian), nationality, date and place of birth and so on: these data could be managed in a more extended version.
A horse can be a mare (if female) or a stud (if male) if it can have sons, even though it does not have any: to be a mare or stud is a qualification that can be acquired by the horse and corresponds to a registration in the Studbook as a breeding horse.
Initial upload
The initial upload of the database with the horses already registered can be performed with instructions like the following:
-
creation of the instance of a horse
CREATE (h1:Horse {id: $registrationId, name: $horseName, birth_year: toInteger($birthYear), gender: $gender, mantle: $mantle })
where $gender can be ‘F’ or ‘M’ and $registrationId is the code that identifies the horse in the Studbook.
-
registration as a breeding horse
for a female horse:
MATCH (h1:Horse {name: $horseName})
SET h1:Mare
or for a male horse:
MATCH (h1:Horse {name: $horseName})
SET h1:Stud
-
creation of the parentship
MATCH (m1:Mare {name: $MareName}) MATCH (h1:Horse {name: $horseName})
MATCH (s1:Stud {name: $StudName}) MATCH (h1:Horse {name: $horseName})
MERGE (m1)-[:DAM_OF]->(h1)
MERGE (s1)-[:SIRE_OF]->(h1)
Here’s a script to upload some data to start:
CREATE INDEX FOR (n:Horse) ON (n.name)
CREATE INDEX FOR (n:Mare) ON (n.name)
CREATE INDEX FOR (n:Stud) ON (n.name)The initial data give the following graph:
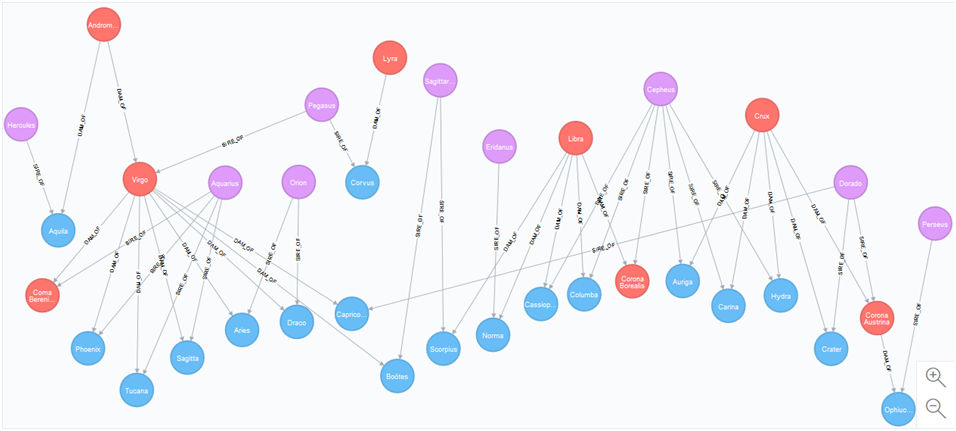
Consistency checks
In order to keep the data correct over time, it is advisable to have some queries for periodic verification of the absence of anomalous situations. They will also be essential after a massive upload of data from an existing database: data are consistent when all of these queries return no results.
-
Not existence of loops:
MATCH (parent)-[*]->(parent)
RETURN COUNT(parent)-
Not existence of two dams or two sires for the same horse:
MATCH (dam1:Mare)-->(h:Horse), (dam2:Mare)-->(h)
WHERE exists((dam1)-->(h)<--(dam2))
RETURN DISTINCT h.name, dam1.name, dam2.nameMATCH (sire1:Stud)-->(h:Horse), (sire2:Stud)-->(h:Horse)
WHERE exists((sire1)-->(h)<--(sire2))
RETURN DISTINCT h.name, sire1.name, sire2.name-
Not existence of a dam with two sons in the same year:
MATCH (horse1:Horse)<--(dam:Mare)-->(horse2:Horse)
WHERE horse1.birth_year = horse2.birth_year
RETURN DISTINCT dam.name, horse1.name, horse2.name-
Not existence of dams or sires too young for their sons:
MATCH (parent:Horse)-->(son:Horse)
WHERE parent.birth_year >= son.birth_year - 2
RETURN DISTINCT parent.name, parent.birth_year, son.name, son.birth_year-
Not existence of dams too old for their sons:
MATCH (dam:Mare)-->(son:Horse)
WHERE dam.birth_year < son.birth_year - 20
RETURN DISTINCT dam.name, dam.birth_year, son.name, son.birth_yearAs for studs, they can have foals even in their late seniority, if the rules of the Studbook allow the use of artificial insemination; otherwise, a similar check must be performed for studs as well.
How to manage data
Now let’s see what we should put in an application that allows us to manage the data of a Studbook.
The first functions are those to register a new horse, a foal, in the Studbook.
-
Registration in the breeding section of the Studbook
Before generating foals eligible for registration, both the future mother (dam) and the future father (sire) must be registered as breeding horses, respectively mare and stud, in the appropriate sections of the Studbook.
For female horses the registration as breeding horse function has to perform the following instruction:
MATCH (h:Horse {name: $name})
WHERE h.gender = 'F' AND NOT h:Mare
SET h:Mare
RETURN h.name as MareName, labels(h) as Labels
For male horses the following instruction is needed:
MATCH (h:Horse {name: $name})
WHERE h.gender = 'M' AND NOT h:Stud
SET h:Stud
RETURN h.name as StudName, labels(h) as Labels
In both instructions the conditions make us sure that:
-
the horse is of the right gender
-
the horse is not already in the register
Only if both the conditions are satisfied, the registration will be performed.
-
Registration of a foal in the Studbook
When a foal is born, it can be registered in the Studbook only if its dam and sire are both registered as well. So the instruction that has to be performed for such an action is the following:
MATCH (sire:Stud {name: $sireName})
MATCH (dam:Mare {name: $dameName})
OPTIONAL MATCH (dam)<-[:SIRE_OF]-(damssire)
CREATE (foal:Horse {id: $registrationId, name: $foalName, birth_year: toInteger($birthYear), gender: $gender, mantle: $mantle})
CREATE (dam)-[:DAM_OF]->(foal)
CREATE (sire)-[:SIRE_OF]->(foal)
RETURN 'Foal registered: ' + foal.name + ' by ' + sire.name + ' out of ' + dam.name + ' (' + damssire.name + ')' as NewFoal
Let’s take a look at the instruction. Firstly, if the dam or the sire are not registered as breeding horses, the corresponding MATCH will have no result (the label filters) and the registration of the foal fails. The OPTIONAL MATCH for the dam’s sire is needed to avoid the match fails when not all dam’s data are immediately available (i.e. if she is imported or in case of genealogy reconstruction).
-
Humans in the model: breeders, owners and tenants
Respecting to a horse, the main roles a person can have are:
-
breeder: who makes it born and raises him at least for a first period;
-
owner: who has the rights on it and does not necessarily coincide with the breeder;
-
tenant: who takes from the owner temporary rights on it.
On one hand, a public deed is sufficient to certify if a person is the owner or tenant of a horse. On the other hand, a person becomes a breeder as owner or tenant of the mare who gives birth to a foal. So, the role that a person can have with a horse arises from the relationship established between the person and the horse.
At the birth, the owner or tenant of the mare automatically becomes either the breeder or the owner of the foal: then, the instruction seen before for foal registration has to be completed in the following way:
MATCH (sire:Stud {name: $sireName})
MATCH (dam:Mare {name: $dameName})
OPTIONAL MATCH (dam)<-[:SIRE_OF]-(damssire)
CREATE (foal:Horse {name: $foalName, birth_year: toInteger($birtYear), gender: $gender, mantle: $mantle})
CREATE (dam)-[:DAM_OF]->(foal)
CREATE (sire)-[:SIRE_OF]->(foal)
WITH sire, dam, damssire, foal
MATCH (dam)<-[ownshp:OWNER_OF]-(owner)
OPTIONAL MATCH (dam)<-[tenshp:TENANT_OF]-(tenant)
WITH sire, dam, damssire, foal, coalesce(tenant, owner) as breeder, coalesce(tenshp, ownshp) as quote
CREATE (breeder)-[:BREEDER_OF {breed_perc: quote.property_perc}]->(foal)
CREATE (breeder)-[:OWNER_OF {property_perc: quote.property_perc}]->(foal)
RETURN DISTINCT 'Foal registered: ' + foal.name + ' by ' + sire.name + ' out of ' + dam.name + ' (' + damssire.name + ')' as NewFoal
Let’s look at it more closely. After creating the new foal and the relations with his parents, the script continues (first WITH) getting the owner and the tenant, if any (OPTIONAL clause), of the dam; then (second WITH) the tenant or owner is chosen as breeder of the foal, in any case with the respective percentage of property (variable quote), and the property and breeding relationships are finally created. The string returned has the typical form for horse naming, with sire, dam and sire of the dam. Obviously, many people can be the owners or tenants of a horse: the script works perfectly even in this case.
To check if all relationships between people and horses are consistent, i.e. the sum of the percentages of each relationship type is 100 for all the horses, the following statement must be added to the consistency checks to be implemented:
MATCH (p:Person)-[r:OWNER_OF]->(h:Horse) WITH h, sum(r.property_perc) as sum_property_perc WHERE sum_property_perc <> 100 RETURN h, sum_property_perc
and analogous for the other types of relationships (:BREEDER_OF, :TENANT_OF).
-
Purchase of a horse
In case of purchase of a horse, the new configuration of property rights can be obtained with the following instructions (here the new owners are three, but they can be from one to n):
MATCH (h:Horse {name: $horseName})
OPTIONAL MATCH (h)<-[oldOwnshp:OWNER_OF]-()
DELETE oldOwnshp
WITH [{name:$newowner1, property_perc: toFloat($perc1)}
, {name:$newowner2, property_perc: toFloat($perc2)}
, {name:$newowner3, property_perc: toFloat($perc3)}
] AS purchaserList
UNWIND purchaserList AS purchaser
MERGE (p:Person {name: purchaser.name})
ON CREATE SET p.property_perc = purchaser.property_perc
ON MATCH SET p.property_perc = purchaser.property_perc
MERGE (p)-[newOwnshp:OWNER_OF]->(h)
SET newOwnshp.property_perc = p.property_perc
REMOVE p.property_perc
RETURN h.name, collect(p.name)
Firstly, the old ownerships, if existing, are deleted. In the WITH statement there is the list of the new owners, each with his/her property percentage. Then the list in UNWINDed to get the table of the new owners. For each new owner, already existing or new in the database, the property percentage is temporarily assigned to him/her; when the new relationships between each new owner and the horse are created, the percentage is assigned to the relationship and the temporary value is removed from the owner.
A similar instruction can be written for rental, while breeding rights normally cannot be sold.
Let’s see Cypher in action
We will now apply the instructions just seen to the data initially entered.
Let’s add some people related to three of the registered horses: their breeders and owners, and a tenant for one of them:
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
CREATE (p1:Person {name: 'Julia Stokes'})
CREATE (p2:Person {name: 'Hugh Kelley'})
CREATE (p3:Person {name: 'Anne Nicholson'})
CREATE (p4:Person {name: 'Jeremy Dalton'})
CREATE (p5:Person {name: 'Beatrice Fowler'})
CREATE (p1)-[:BREEDER_OF {breed_perc: toFloat(100.0)}]-> (h1)
CREATE (p1)-[:OWNER_OF {property_perc: toFloat(100.0)}]-> (h1)
CREATE (p2)-[:BREEDER_OF {breed_perc: toFloat(100.0)}]-> (h2)
CREATE (p3)-[:OWNER_OF {property_perc: toFloat(60.0)}]-> (h2)
CREATE (p4)-[:OWNER_OF {property_perc: toFloat(40.0)}]-> (h2)
CREATE (p5)-[:BREEDER_OF {breed_perc: toFloat(100.0)}]-> (h3)
CREATE (p5)-[:OWNER_OF {property_perc: toFloat(100.0)}]-> (h3)
CREATE (p3)-[:TENANT_OF {rental_perc: toFloat(100.0)}]-> (h3)
RETURN h1,h2,h3,p1,p2,p3,p4,p5The situation is as follows, where all three horses are in blue because none of them is a breeding horse yet:
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
MATCH (p1)-[r1:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h1)
MATCH (p2)-[r2:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h2)
MATCH (p3)-[r3:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h3)
RETURN h1,h2,h3,p1,p2,p3,r1,r2,r3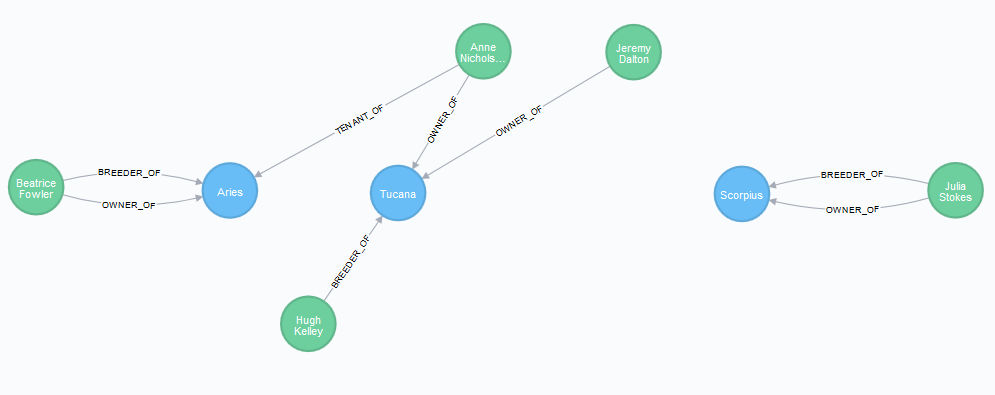
In order to have a new foal, Tucana and Scorpius have to become breeding horses:
MATCH (h:Horse {name: 'Tucana'})
WHERE h.gender = 'F' AND NOT h:Mare
SET h:Mare
RETURN h.name as MareName, labels(h) as LabelsMATCH (h:Horse {name: 'Scorpius'})
WHERE h.gender = 'M' AND NOT h:Stud
SET h:Stud
RETURN h.name as StudName, labels(h) as LabelsThe situation is now the following, in which Scorpius is red as a stud, Tucana is purple as a mare:
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
MATCH (p1)-[r1:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h1)
MATCH (p2)-[r2:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h2)
MATCH (p3)-[r3:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h3)
RETURN h1,h2,h3,p1,p2,p3,r1,r2,r3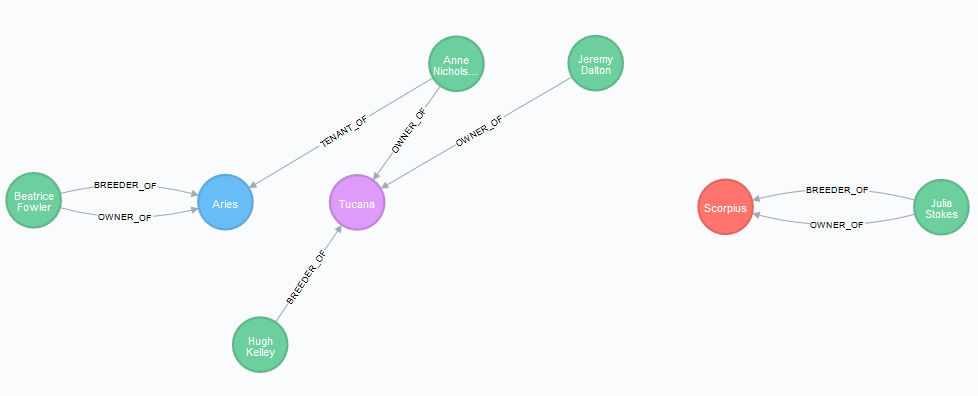
Let’s suppose that Tucana and Scorpius give birth to a foal, Saturn:
MATCH (sire:Stud {name: 'Scorpius'})
MATCH (dam:Mare {name: 'Tucana'})
OPTIONAL MATCH (dam)<-[:SIRE_OF]-(damssire)
CREATE (foal:Horse {name: 'Saturn', birth_year: toInteger(2018), gender: 'M', mantle: 'bay'})
CREATE (dam)-[:DAM_OF]->(foal)
CREATE (sire)-[:SIRE_OF]->(foal)
WITH sire, dam, damssire, foal
MATCH (dam)<-[ownshp:OWNER_OF]-(owner)
OPTIONAL MATCH (dam)<-[tenshp:TENANT_OF]-(tenant)
WITH sire, dam, damssire, foal, coalesce(tenant, owner) as breeder, coalesce(tenshp, ownshp) as quote
CREATE (breeder)-[:BREEDER_OF {breed_perc: quote.property_perc}]->(foal)
CREATE (breeder)-[:OWNER_OF {property_perc: quote.property_perc}]->(foal)
RETURN DISTINCT 'Foal registered: ' + foal.name + ', by ' + sire.name + ' out of ' + dam.name + ' (' + damssire.name + ')' as NewFoalThe new situation is the following:
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
MATCH (h4:Horse {name: 'Saturn'})
MATCH (p1)-[r1:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h1)
MATCH (p2)-[r2:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h2)
MATCH (p3)-[r3:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h3)
MATCH (p4)-[r4:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h4)
MATCH (h1)-[r5:SIRE_OF]->(h4)<-[r6:DAM_OF]-(h2)
RETURN h1,h2,h3,h4,p1,p2,p3,p4,r1,r2,r3,r4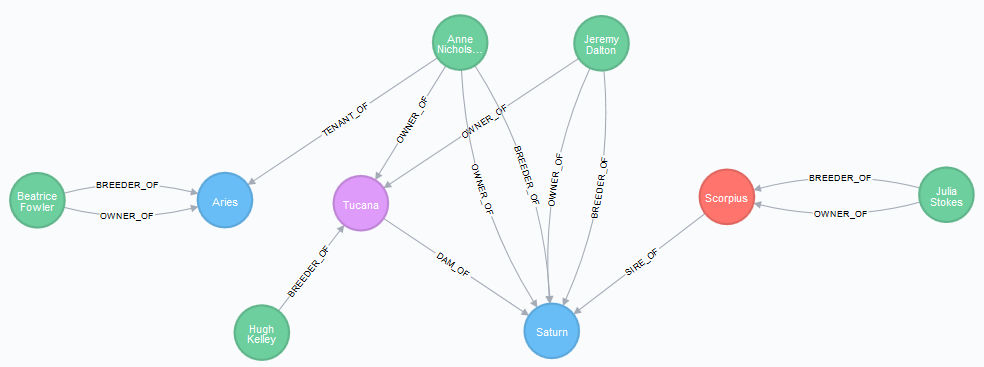
You can see that the breeders and owners of Saturn are the owners of his dam Tucana, Anne Nicholson and Jeremy Dalton, with the same percentages of rights they have on the mare, respectively 60% and 40%:
MATCH (h:Horse {name: 'Saturn'})
MATCH (h)<-[r:OWNER_OF]-(p)
RETURN p.name, r.property_percMATCH (h:Horse {name: 'Saturn'})
MATCH (h)<-[r:BREEDER_OF]-(p)
RETURN p.name, r.breed_percLet’s suppose now that the new foal is sold to Julia Stokes, Hugh Kelley and Philip Lindsey (the last is new in the database), respectively with the property percentages of 25%, 25% and 50%.
MATCH (h:Horse {name: 'Saturn'})
OPTIONAL MATCH (h)<-[oldOwnshp:OWNER_OF]-()
DELETE oldOwnshp
WITH DISTINCT h, [{name:'Julia Stokes', property_perc: toFloat(25)}, {name:'Hugh Kelley', property_perc: toFloat(25)}, {name:'Philip Lindsey', property_perc: toFloat(50)}] AS purchaserList
UNWIND purchaserList AS purchaser
MERGE (p:Person {name: purchaser.name})
ON CREATE SET p.property_perc = purchaser.property_perc
ON MATCH SET p.property_perc = purchaser.property_perc
CREATE (p)-[newOwnshp:OWNER_OF {property_perc: p.property_perc}]->(h)
REMOVE p.property_perc
RETURN p.name, type(newOwnshp), newOwnshp.property_percand the final situation is the following:
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
MATCH (h4:Horse {name: 'Saturn'})
MATCH (p1)-[r1:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h1)
MATCH (p2)-[r2:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h2)
MATCH (p3)-[r3:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h3)
MATCH (p4)-[r4:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h4)
MATCH (h1)-[]->(h4)<-[]-(h2)
RETURN h1,h2,h3,h4,p1,p2,p3,p4,r1,r2,r3,r4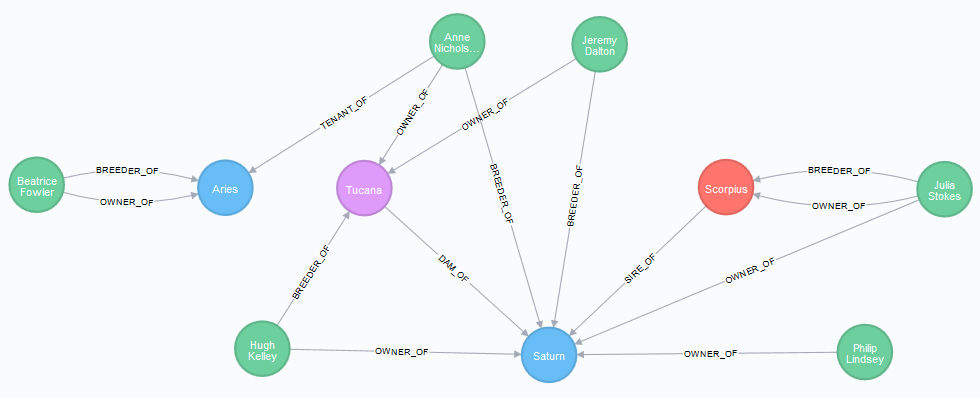
We can check if the property rights are correct:
MATCH (h:Horse {name: 'Saturn'})
MATCH (h)<-[r:OWNER_OF]-(p)
RETURN p.name, r.property_percThat’s right!
With the instructions seen we can build an application that let us manage a Studbook in a natural and easy way.
Data querying
The typical queries a user can ask a Studbook are those related to information about a horse, its ancestors and descendants, the people who own it or manage it. Let’s see some of these queries.
-
Horse’s pedigree
The main part of the pedigree shows the data of the horse and those of parents and grandparents (often of the grand-grandparents as well):
MATCH (h:Horse {name: 'Saturn'})
OPTIONAL MATCH (h)<-[:DAM_OF]-(dam:Mare)
OPTIONAL MATCH (h)<-[:SIRE_OF]-(sire:Stud)
OPTIONAL MATCH (dam)<-[:DAM_OF]-(damsdam:Mare)
OPTIONAL MATCH (dam)<-[:SIRE_OF]-(damssire:Stud)
OPTIONAL MATCH (sire)<-[:DAM_OF]-(siresdam:Mare)
OPTIONAL MATCH (sire)<-[:SIRE_OF]-(siressire:Stud)
RETURN h.name as Name, h.gender as Gender, h.birth_year as Birth_year, h.mantle as Mantle, sire.name as Sire_name, sire.birth_year as Sire_birth_year, sire.mantle as Sire_mantle, siressire.name as Sire_of_sire, siresdam.name as Dam_of_sire, dam.name as Dam_name, dam.birth_year as Dam_birth_year, dam.mantle as Dam_mantle, damssire.name as Sire_of_dam, damsdam.name as Dam_of_dam-
Maternal ancestry
Another typical section of the pedigree is related to maternal ancestry, or the list of the mothers up to 3rd (or 4th) generation:
MATCH (h:Horse {name: 'Saturn'})
OPTIONAL MATCH (h)<-[:DAM_OF]-(d1:Horse)
OPTIONAL MATCH (d1)<-[:DAM_OF]-(d2:Horse)
OPTIONAL MATCH (d2)<-[:DAM_OF]-(d3:Horse)
RETURN h.name AS Name, h.birth_year AS Birth, d1.name AS FirstMother, d1.birth_year AS FMBirth, d2.name AS SecondMother, d2.birth_year AS SMBirth, d3.name AS ThirdMother, d3.birth_year AS TMBirth-
Horse’s descendants
Obviously, if a horse has descendants, it is important to know how many they are and from which parents:
MATCH (h:Horse {name: 'Cepheus'})
OPTIONAL MATCH (h)-->(d:Horse)
OPTIONAL MATCH (d)<--(p:Horse) WHERE p.name <> h.name
RETURN h.name as Name, h.gender as Gender, h.birth_year as Birth, h.mantle as Mantle, d.name as Descendant, d.gender as DGender, d.birth_year as DBirth, p.name as DParent, p.birth_year as DParent_birth
ORDER BY d.birth_yearMATCH (h:Horse {name: 'Virgo'})
OPTIONAL MATCH (h)-->(d:Horse)
OPTIONAL MATCH (d)<--(p:Horse) WHERE p.name <> h.name
RETURN h.name as Name, h.gender as Gender, h.birth_year as Birth, h.mantle as Mantle, d.name as Descendant, d.gender as DGender, d.birth_year as DBirth, p.name as DParent, p.birth_year as DParent_birth
ORDER BY d.birth_yearConclusions
We have seen how easy and natural it is to see the data of a Studbook on a graph and how clear are the instructions to manage them.
I hope you enjoyed this gist and can get from it some hints for a real application. As I said before, the data model can be enhanced a lot, adding additional attributes to instances or refactoring some aspects, such as time or nationality (year of birth or nation as nodes): and from the point of view of refactoring you will see that Neo4j allows you to enhance information on the nodes and relationships in a way that is much smoother and flexible to do than with a relational DBMS, keeping on the one hand the benefits of a true relational structure, but on the other enjoying the advantages of a free-structure database.
Have a good time!
Is this page helpful?